
In Setting Destination, we pictured Zedge‑style “smart sidekicks” co‑creating, curating, and enriching.(Zedge Blog) This follow‑up is the pragmatic sequel: how agentic systems are actually built, where they shine, where they stall, and how they’re evolving - without losing the curiosity that got us here.
Agentic AI = systems that plan, act with tools, remember, and adapt. The ecosystem now ships this out of the box: OpenAI’s Responses API + Agents SDK add first‑party tools (web search, file search, computer use), session state, handoffs, and tracing; Anthropic’s Computer Use lets Claude operate the desktop when APIs don’t exist. These aren’t just chatbots; they’re action systems with audit trails.
The Evolution of Agents (2023 → 2025)
That arc echoes the design framing in Stop Prompting, Start Designing: 5 Agentic AI Patterns That Actually Work - but below we go deeper on how to ship each pattern. DEV Community
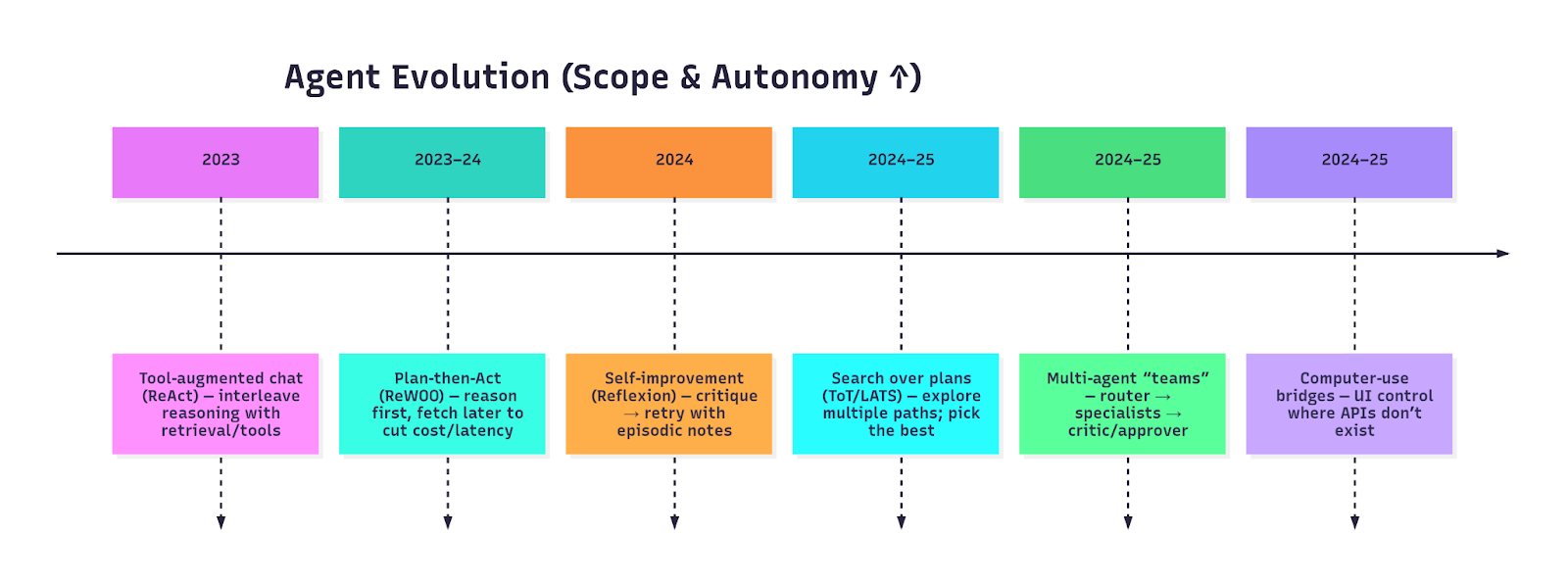
Patterns that actually work (flows + build tips)
1) ReAct — Interleave reasoning with tool‑use
Default for retrieval/browsing/short, multi‑step tasks; reduces hallucinations by forcing evidence.
Implementation tips
- Use typed tool schemas (reject malformed URLs/IDs); allow‑list tools and params.
- Log every think/act/observe step; keep tool I/O in your trace for audit/RCA.
- ReAct remains a strong baseline for knowledge tasks and simple web flows. arXiv

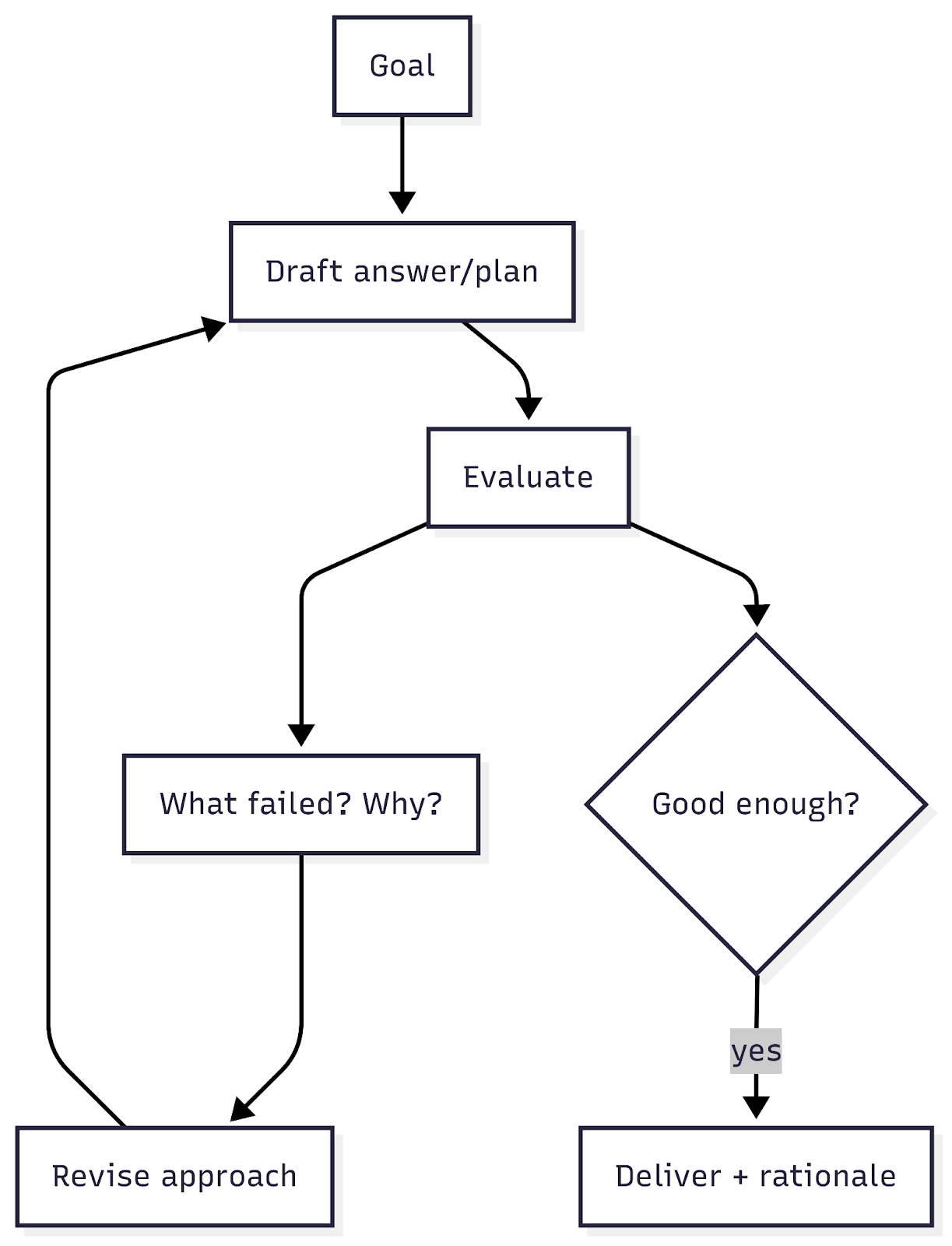
2) Reflexion - Self‑critique, then retry
Cheap quality lift when you can validate an answer (tests, heuristics, rules).
Implementation tips
- Cap to 1-2 retries; require a pass/fail predicate (unit test, regex, score).
- Store reflections as episodic notes (short‑term memory), distinct from long‑term.
- Expose reflections in traces so humans learn too. arXivGitHub
3) Plan‑then‑Act (ReWOO) - Reason first, fetch later
Cuts token cost/latency by separating “thinking” from “gathering.”
Implementation tips
- Treat evidence as a typed artifact (JSON/Markdown) with size caps; cache by (tool, query, params).
- Fail fast if a planned tool isn’t reachable; re‑plan with cheaper backoff.
- Reported 5× token efficiency on HotpotQA in the paper’s evaluations. arXivOpenReview

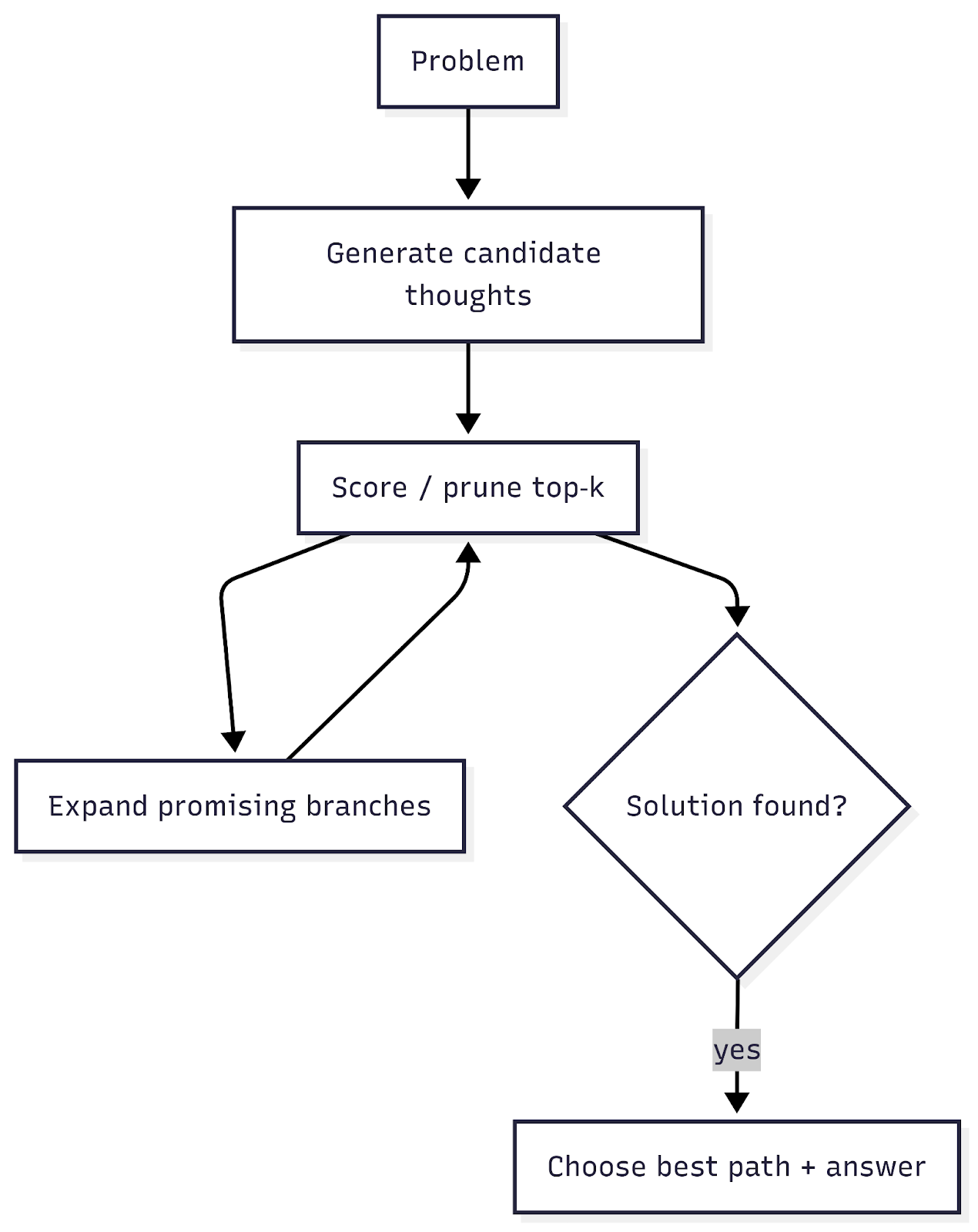
4) Tree‑of‑Thoughts / LATS - Explore multiple paths
For thorny planning/coding/web tasks: generate candidate “thoughts,” prune, expand; pick the best path.
Implementation tips
- Bound breadth/depth; use a value function (LLM self‑rating or heuristics).
- Persist each branch’s artifacts to tracing for RCA.
- LATS unifies reasoning + acting + planning via MCTS; effective for programming/web. arXiv+1
5) Multi‑agent “teams” - Router → specialists → critic/approver
Compose skills, isolate risk, keep approvals where it matters.
Implementation tips
- Keep each specialist’s tool surface area tiny; typed contracts only.
- Use handoffs for clean delegation; approvals appear in the trace by default.
- Track per‑role SLAs (latency, quality, intervention rate). OpenAI PlatformOpenAI GitHub

Toolbox (single glance)
- PydanticAI - “FastAPI‑for‑agents” DX: typed tools & strict I/O validation, generic type‑safe agents, and pydantic‑graph under the hood. Great for contracts and guardrails.
- OpenAI Responses API + Agents SDK - stateful runs, first‑party tools (web/file search, computer use), handoffs, guardrails, and built‑in tracing.
- Anthropic Computer Use - desktop control via screenshot/mouse/keyboard for legacy UI flows (beta). Anthropic
Where it shines (public wins to learn from)
- Consumer support at scale - Klarna: assistant handled ~two‑thirds of chats in month one (≈2.3M conversations), with major time/cost gains. Narrow scope + approvals = speed + trust. PR Newswire
- Enterprise coding - GitHub Copilot Coding Agent: assign issues, open PRs, and tag you for review; available across Business/Enterprise plans; runs in a secure, cloud‑hosted dev environment. GitHub DocsThe GitHub Bl
- E‑commerce copilot - Shopify Sidekick: merchant assistant launched via early access, now sharing production lessons on evals and GRPO training. The VergeShopify
- Cloud IDE autonomy - Amazon Q Developer: agentic coding inside VS Code (actions on your behalf), with iterative updates across code review, tests, and docs. Amazon Web Services, Inc.+1
Pattern fit: ReAct/ReWOO for support & analytics; multi‑agent + approvals for coding & enterprise workflows; computer‑use when you must cross legacy UI.
Reality checks (a/k/a the limits)
Benchmarks that simulate “real work” remain sobering:
- WebArena & VisualWebArena: realistic websites + visually grounded tasks expose brittleness in multi‑step UI flows and visual grounding. arXiv+1
- AgentBench: across 8 environments, failures cluster in long‑term reasoning/decision‑making - agents need tighter scaffolding and evaluation. arXiv
- SWE‑bench: real GitHub issues remain hard; naive autonomy disappoints without tests, sandboxes, and review gates. arXiv
Design consequences
- Stay narrow: crisp goals, bounded steps, explicit success checks.
- Prefer short horizons: many simple plans >> one heroic chain.
- Trace everything: if you can’t inspect plan/tool calls, you can’t improve them.
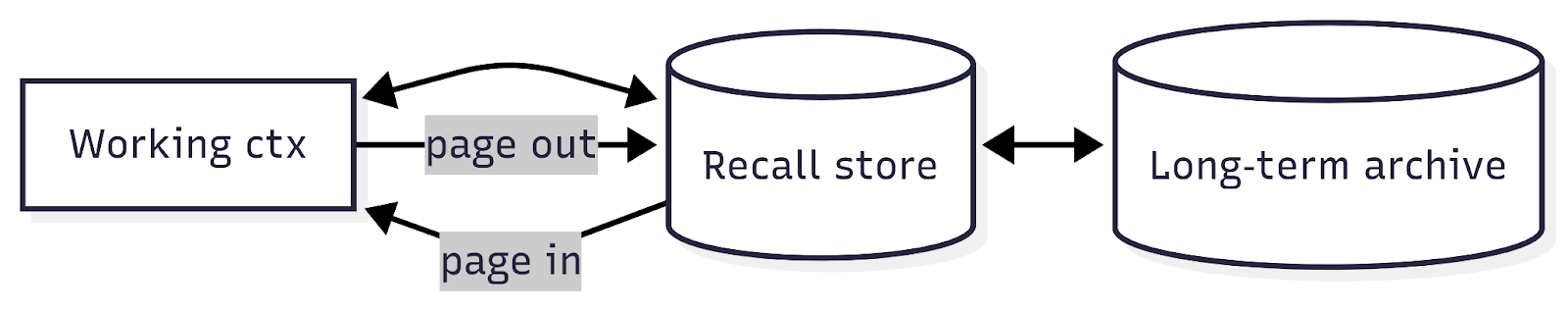
Memory that lasts (without monstrous prompts)
Long‑lived assistants need OS‑style virtual memory: short‑term working context ↔ recall store ↔ long‑term archive. MemGPT formalizes this “paging” model so agents remember across sessions—without stuffing the prompt. arXiv
Security & governance (practical, not preachy)
- Least‑privilege tools, time‑boxed creds; allow‑list domains/APIs for browsing.
- Typed tool I/O and schema validation on every hop (your easiest win).
- Approval gates for state‑changing actions; immutable traces for audit/RCA.
So… what does “limits of unlimited” really mean?
The promise is huge - but unbounded autonomy is a myth (for now). Agents don’t win because they do everything. They win because they do some things extremely well:
- Tight scopes with observable steps.
- Patterns that balance planning with evidence.
- Typed contracts that make tool‑use safe and predictable.
- Human approvals where stakes are high.
Where we go next (optimistic, and specific)
- UI‑native agents become normal: “computer‑use” grows up, pairing with design systems so agents reliably click/type/verify across apps. Anthropic
- Memory becomes skill: OS‑like paging (MemGPT) merges with reusable “procedures” learned from past runs-less prompting, more doing. arXiv
- Evaluation goes CI: web/visual/coding benchmarks turn into continuous gates; we ship behind tests, not vibes. arXiv+2arXiv+2
- Governance productizes: tracing dashboards + NIST profiles + OWASP checks feel like linting for autonomy - limits as a feature, not a bug. OpenAI GitHub
We can still be dreamers. The trick is dreaming with guardrails - so the horizon keeps getting closer, one reliable handoff at a time.